2024.04.19 - [Architecture/A.I] - ai? 맨땅에 헤딩 -1(langChain) : ai와 공생하기!
langChain의 친구들은 아래와 같습니다.
나중에 하나씩 알아보도록해요:)

이제 LangChain에 대해서 알아보겠습니다.
LangChain is a framework for developing applications powered by large language models (LLMs).
LLM을 가지고 개발할 수 있게 도와주는 프레임워크였군요!!
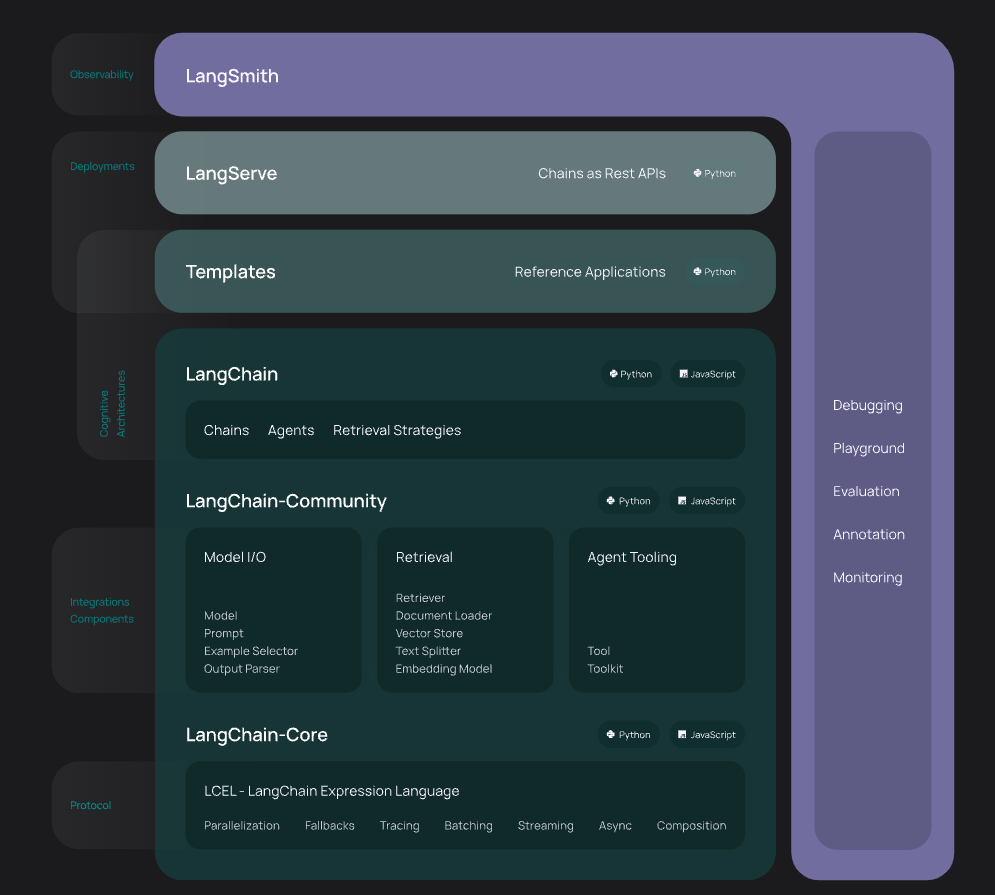
개발은 LangChain의 오픈소스 building blocks과 components를 사용 합니다.
또한 third-party integrations와 Templates를 사용 합니다.
LangSmith를 사용해서 chains를 검사하고 모니터링 및 평가 합니다.
또한 지속적으로 최적화하며 배포할 수 있습니다.
배포는 LangServe를 가지고 모든 chain을 api로 변경할 수 있습니다.
LangChain 구축방법은?
1. 프롬프트 템플릿의 정보에 의존하여 응답하는 간단한 LLM 체인부터 시작
2. 별도의 데이터베이스에서 데이터를 가져와 프롬프트 템플릿으로 전달하는 검색 체인을 구축
3. 그 다음으로 채팅 기록을 추가하여 대화 검색 체인을 만듭니다.
이를 통해 이 LLM과 채팅 방식으로 상호 작용할 수 있으므로 이전 질문을 기억합니다.
4. 마지막으로 LLM을 활용하여 질문에 답변하기 위해 데이터를 가져와야 하는지 여부를 결정하는 에이전트를 구축합니다.
1. LLM Chain
: 프롬프트 템플릿의 정보에 의존하여 응답하는 간단한 LLM 체인부터 시작
pip inatall langchain-openai
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
print(llm.invoke("how can langsmith help with testing?"))답변:
content = 'Langsmith can help with testing in several ways:\n\n1.
Automated testing: Langsmith can be used to create test scripts
and automate the testing process,
saving time and reducing the risk of human error.\n\n2.
Performance testing: Langsmith can be used to simulate large numbers of users
and test the performance of a system under heavy load.\n\n3.
Regression testing: Langsmith can be used to quickly run tests
on new versions of software to ensure that existing functionality
has not been broken.\n\n4. API testing: Langsmith can be used to test
the functionality of APIs by sending requests and validating responses.\n\n
5. Data-driven testing: Langsmith can be used to test multiple scenarios
by parameterizing test data and running tests with different inputs.\n\n
Overall, Langsmith can help streamline the testing process, improve test coverage,
and ensure the quality of software applications.'
response_metadata = {
'token_usage': {
'completion_tokens': 169,
'prompt_tokens': 15,
'total_tokens': 184
},
'model_name': 'gpt-3.5-turbo',
'system_fingerprint': 'fp_c2273ad',
'finish_reason': 'stop',
'logprobs': None
}
id = 'run-62712-2264-4cb4-bf31-0968f-0'위 내용처럼 LLM모델을 손쉽게 연결해서 사용할 수 있습니다.(chain)
또한 prompt와 llm을 쉽게 연결 합니다.
chain = prompt | llm
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_messages([
("system", "You are a world class technical documentation writer."),
("user", "{input}")
])
llm = ChatOpenAI()
chain = prompt | llm
print(chain.invoke({"input": "how can langsmith help with testing?"}))답변:

from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
output은 메시지이며 동작시키면 답변이 깔끔하게 나옵니다.

from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_messages([
("system", "You are a world class technical documentation writer."),
("user", "{input}")
])
llm = ChatOpenAI()
output_parser = StrOutputParser()
chain = prompt | llm | output_parser
print(chain.invoke({"input": "how can langsmith help with testing?"}))2. Retrieval Chain
: 별도의 데이터베이스에서 데이터를 가져와 프롬프트 템플릿으로 전달하는 검색 체인을 구축
검색은 LLM에 직접 전달하기에는 데이터가 너무 많은 경우에 유용합니다.
그런 다음 검색기를 사용하여 가장 관련성이 높은 부분만 가져와서 전달할 수 있습니다.
이 과정에서 우리는 Retriever로부터 관련 문서를 조회한 후 이를 프롬프트에 전달합니다.
Retriever는 SQL 테이블, 인터넷 등 무엇이든 지원될 수 있지만 이 경우 벡터 저장소를 채워 이를 Retriever로 사용하겠습니다.
벡터스토어에 대한 자세한 내용은 이 문서를 참조하세요. (클릭)
먼저, 인덱싱하려는 데이터를 로드해야 합니다.
이를 위해 WebBaseLoader를 사용합니다.
이를 위해서는 BeautifulSoup 설치가 필요합니다
pip3 install beautifulsoup4그런 다음에 WebBaseLoader 코드를 작성 합니다.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://docs.smith.langchain.com/user_guide")
docs = loader.load()Next, we need to index it into a vectorstore.
필요한것은 embedding model과 vectorstore 입니다.

from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()이제 이 임베딩 모델을 사용하여 문서를 벡터 저장소에 수집할 수 있습니다.
단순화를 위해 간단한 로컬 벡터 저장소인 FAISS를 사용하겠습니다.
pip3 install faiss-cpu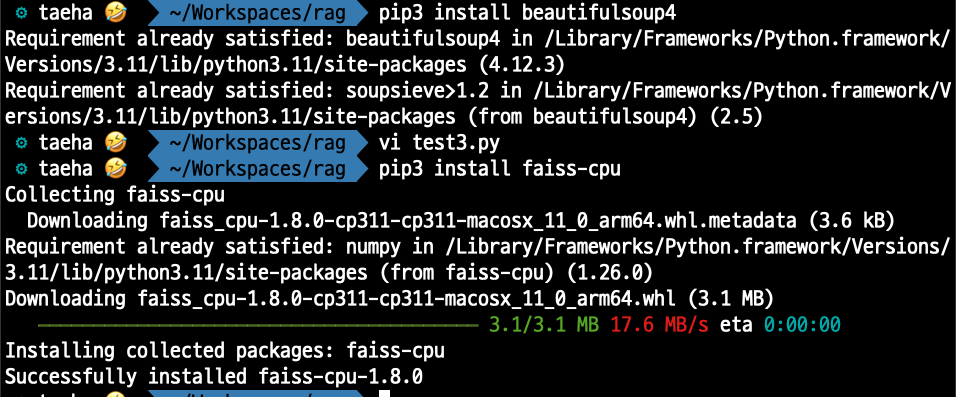
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)이제 이 데이터를 벡터 저장소에 색인화했으므로 검색 체인을 생성하겠습니다.
이 체인은 들어오는 질문을 받아 관련 문서를 찾은 다음 해당 문서를
원래 질문과 함께 LLM에 전달하고 원래 질문에 답하도록 요청합니다.
먼저 질문과 검색된 문서를 가져와 답변을 생성하는 체인을 설정해 보겠습니다.
from langchain.chains.combine_documents import create_stuff_documents_chain
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)원한다면 문서를 직접 전달하여 직접 실행할 수도 있습니다.
from langchain_core.documents import Document
document_chain.invoke({
"input": "how can langsmith help with testing?",
"context": [Document(page_content="langsmith can let you visualize test results")]
})그러나 우리는 방금 설정한 Retrieval에서 먼저 문서를 가져오길 원합니다.
이렇게 하면 Retrieval를 사용하여 가장 관련성이 높은 문서를 동적으로 선택하고 주어진 질문에 대해 해당 문서를 전달할 수 있습니다.
from langchain.chains import create_retrieval_chain
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)이제 이 체인을 호출할 수 있습니다.
그러면 사전이 반환됩니다.
LLM의 응답은 답변 키에 있습니다.
response = retrieval_chain.invoke({"input": "how can langsmith help with testing?"})
print(response["answer"])
# LangSmith offers several features that can help with testing:...위 내용들을 정리하면 아래와 같은 소스가 나옵니다.
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
# loader
loader = WebBaseLoader("https://docs.smith.langchain.com/user_guide")
docs = loader.load()
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)
#retriever
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# invoke
response = retrieval_chain.invoke({"input": "how can langsmith help with testing?"})
print(response["answer"])답변:

3. Conversation Retrieval Chain
: 채팅 기록을 추가하여 대화 검색 체인을 만듭니다.
지금까지 우리가 만든 체인은 단 하나의 질문에만 답할 수 있습니다.
사람들이 구축하는 LLM 애플리케이션의 주요 유형 중 하나는 채팅 봇입니다.
그렇다면 이 체인을 후속 질문에 답할 수 있는 체인으로 어떻게 바꾸나요?
create_retrieval_chain 함수를 계속 사용할 수 있지만 다음 두 가지를 변경해야 합니다.
검색 방법은 이제 가장 최근 입력에만 적용되는 것이 아니라 전체 기록을 고려해야 합니다.
최종 LLM 체인도 마찬가지로 전체 기록을 고려해야 합니다.
Updating Retrieval
검색을 업데이트하기 위해 새 체인을 생성합니다.
이 체인은 가장 최근 입력(input)과 대화 기록(chat_history)을 받아들이고
LLM을 사용하여 검색 쿼리를 생성합니다.
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
# First we need a prompt that we can pass into an LLM to generate this search query
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
("user", "Given the above conversation, generate a search query to look up to get information relevant to the conversation")
# 위의 대화를 바탕으로 대화와 관련된 정보를 얻기 위해 조회할 검색어를 생성합니다.
])
retriever_chain = create_history_aware_retriever(llm, retriever, prompt)사용자가 후속 질문을 하는 인스턴스를 전달하여 이를 테스트할 수 있습니다.
from langchain_core.messages import HumanMessage, AIMessage
chat_history = [HumanMessage(content="Can LangSmith help test my LLM applications?"), AIMessage(content="Yes!")]
retriever_chain.invoke({
"chat_history": chat_history,
"input": "Tell me how"
})그러면 LangSmith의 테스트에 관한 문서가 반환되는 것을 볼 수 있습니다.
아래의 스크린샷에서 기존과
이는 LLM이 채팅 기록과 후속 질문을 결합하여 새로운 쿼리를 생성했기 때문입니다.
기존
후속질문과 결합

후속질문과 결합 소스
from langchain_core.messages import HumanMessage, AIMessage
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
# loader
loader = WebBaseLoader("https://docs.smith.langchain.com/user_guide")
docs = loader.load()
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)
#retriever
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
("user", "Given the above conversation, generate a search query to look up to get information relevant to the conversation")
# 위의 대화를 바탕으로 대화와 관련된 정보를 얻기 위해 조회할 검색어를 생성합니다.
])
retriever_chain = create_history_aware_retriever(llm, retriever, prompt)
chat_history = [HumanMessage(content="Can LangSmith help test my LLM applications?"), AIMessage(content="Yes!")]
retriever_chain.invoke({
"chat_history": chat_history,
"input": "Tell me how"
})
# invoke
response = retrieval_chain.invoke({"input": "how can langsmith help with testing?"})
print(response["answer"])
이제 이 새로운 검색기가 있으므로 검색된 문서를 염두에 두고 대화를 계속하기 위해 새 체인을 만들 수 있습니다.
prompt = ChatPromptTemplate.from_messages([
("system", "Answer the user's questions based on the below context:\n\n{context}"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
])
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever_chain, document_chain)위의 코드와 더불어 아래의 코드로 수정하여 테스트를 할 수 있습니다.
chat_history = [HumanMessage(content="Can LangSmith help test my LLM applications?"), AIMessage(content="Yes!")]
retrieval_chain.invoke({
"chat_history": chat_history,
"input": "Tell me how"
})결과 :
{
'chat_history': [HumanMessage(content = 'Can LangSmith help test my LLM applications?'), AIMessage(content = 'Yes!')],
'input': 'Tell me how',
'context': [Document(page_content = 'Skip to main contentLangSmith API DocsSearchGo to AppQuick StartUser GuideTracingEvaluationProduction Monitoring & AutomationsPrompt HubProxyPricingSelf-HostingCookbookUser GuideOn this pageLangSmith User GuideLangSmith is a platform for LLM application development, monitoring, and testing. In this guide, we’ll highlight the breadth of workflows LangSmith supports and how they fit into each stage of the application development lifecycle. We hope this will inform users how to best utilize this powerful platform or give them something to consider if they’re just starting their journey.Prototyping\u200bPrototyping LLM applications often involves quick experimentation between prompts, model types, retrieval strategy and other parameters.\nThe ability to rapidly understand how the model is performing — and debug where it is failing — is incredibly important for this phase.Debugging\u200bWhen developing new LLM applications, we suggest having LangSmith tracing enabled by default.\nOftentimes, it isn’t necessary to look at every single trace. However, when things go wrong (an unexpected end result, infinite agent loop, slower than expected execution, higher than expected token usage), it’s extremely helpful to debug by looking through the application traces. LangSmith gives clear visibility and debugging information at each step of an LLM sequence, making it much easier to identify and root-cause issues.\nWe provide native rendering of chat messages, functions, and retrieve documents.Initial Test Set\u200bWhile many developers still ship an initial version of their application based on “vibe checks”, we’ve seen an increasing number of engineering teams start to adopt a more test driven approach. LangSmith allows developers to create datasets, which are collections of inputs and reference outputs, and use these to run tests on their LLM applications.\nThese test cases can be uploaded in bulk, created on the fly, or exported from application traces. LangSmith also makes it easy to run custom evaluations (both LLM and heuristic based) to score test results.Comparison View\u200bWhen prototyping different versions of your applications and making changes, it’s important to see whether or not you’ve regressed with respect to your initial test cases.\nOftentimes, changes in the prompt, retrieval strategy, or model choice can have huge implications in responses produced by your application.\nIn order to get a sense for which variant is performing better, it’s useful to be able to view results for different configurations on the same datapoints side-by-side. We’ve invested heavily in a user-friendly comparison view for test runs to track and diagnose regressions in test scores across multiple revisions of your application.Playground\u200bLangSmith provides a playground environment for rapid iteration and experimentation.\nThis allows you to quickly test out different prompts and models. You can open the playground from any prompt or model run in your trace.', metadata = {
'source': 'https://docs.smith.langchain.com/user_guide',
'title': 'LangSmith User Guide | 🦜️🛠️ LangSmith',
'description': 'LangSmith is a platform for LLM application development, monitoring, and testing. In this guide, we’ll highlight the breadth of workflows LangSmith supports and how they fit into each stage of the application development lifecycle. We hope this will inform users how to best utilize this powerful platform or give them something to consider if they’re just starting their journey.',
'language': 'en'
}), Document(page_content = 'LangSmith User Guide | 🦜️🛠️ LangSmith', metadata = {
'source': 'https://docs.smith.langchain.com/user_guide',
'title': 'LangSmith User Guide | 🦜️🛠️ LangSmith',
'description': 'LangSmith is a platform for LLM application development, monitoring, and testing. In this guide, we’ll highlight the breadth of workflows LangSmith supports and how they fit into each stage of the application development lifecycle. We hope this will inform users how to best utilize this powerful platform or give them something to consider if they’re just starting their journey.',
'language': 'en'
}), Document(page_content = "Every playground run is logged in the system and can be used to create test cases or compare with other runs.Beta Testing\u200bBeta testing allows developers to collect more data on how their LLM applications are performing in real-world scenarios. In this phase, it’s important to develop an understanding for the types of inputs the app is performing well or poorly on and how exactly it’s breaking down in those cases. Both feedback collection and run annotation are critical for this workflow. This will help in curation of test cases that can help track regressions/improvements and development of automatic evaluations.Capturing Feedback\u200bWhen launching your application to an initial set of users, it’s important to gather human feedback on the responses it’s producing. This helps draw attention to the most interesting runs and highlight edge cases that are causing problematic responses. LangSmith allows you to attach feedback scores to logged traces (oftentimes, this is hooked up to a feedback button in your app), then filter on traces that have a specific feedback tag and score. A common workflow is to filter on traces that receive a poor user feedback score, then drill down into problematic points using the detailed trace view.Annotating Traces\u200bLangSmith also supports sending runs to annotation queues, which allow annotators to closely inspect interesting traces and annotate them with respect to different criteria. Annotators can be PMs, engineers, or even subject matter experts. This allows users to catch regressions across important evaluation criteria.Adding Runs to a Dataset\u200bAs your application progresses through the beta testing phase, it's essential to continue collecting data to refine and improve its performance. LangSmith enables you to add runs as examples to datasets (from both the project page and within an annotation queue), expanding your test coverage on real-world scenarios. This is a key benefit in having your logging system and your evaluation/testing system in the same platform.Production\u200bClosely inspecting key data points, growing benchmarking datasets, annotating traces, and drilling down into important data in trace view are workflows you’ll also want to do once your app hits production.However, especially at the production stage, it’s crucial to get a high-level overview of application performance with respect to latency, cost, and feedback scores. This ensures that it's delivering desirable results at scale.Online evaluations and automations allow you to process and score production traces in near real-time.Additionally, threads provide a seamless way to group traces from a single conversation, making it easier to track the performance of your application across multiple turns.Monitoring and A/B Testing\u200bLangSmith provides monitoring charts that allow you to track key metrics over time. You can expand to view metrics for a given period and drill down into a specific data point to get a trace table for that time period — this is especially handy for debugging production issues.LangSmith also allows for tag and metadata grouping, which allows users to mark different versions of their applications with different identifiers and view how they are performing side-by-side within each chart. This is helpful for A/B testing changes in prompt, model, or retrieval strategy.Automations\u200bAutomations are a powerful feature in LangSmith that allow you to perform actions on traces in near real-time. This can be used to automatically score traces, send them to annotation queues, or send them to datasets.To define an automation, simply provide a filter condition, a sampling rate, and an action to perform. Automations are particularly helpful for processing traces at production scale.Threads\u200bMany LLM applications are multi-turn, meaning that they involve a series of interactions between the user and the application. LangSmith provides a threads view that groups traces from a single conversation together, making it easier to", metadata = {
'source': 'https://docs.smith.langchain.com/user_guide',
'title': 'LangSmith User Guide | 🦜️🛠️ LangSmith',
'description': 'LangSmith is a platform for LLM application development, monitoring, and testing. In this guide, we’ll highlight the breadth of workflows LangSmith supports and how they fit into each stage of the application development lifecycle. We hope this will inform users how to best utilize this powerful platform or give them something to consider if they’re just starting their journey.',
'language': 'en'
}), Document(page_content = 'meaning that they involve a series of interactions between the user and the application. LangSmith provides a threads view that groups traces from a single conversation together, making it easier to track the performance of and annotate your application across multiple turns.Was this page helpful?PreviousQuick StartNextOverviewPrototypingBeta TestingProductionCommunityDiscordTwitterGitHubDocs CodeLangSmith SDKPythonJS/TSMoreHomepageBlogLangChain Python DocsLangChain JS/TS DocsCopyright © 2024 LangChain, Inc.', metadata = {
'source': 'https://docs.smith.langchain.com/user_guide',
'title': 'LangSmith User Guide | 🦜️🛠️ LangSmith',
'description': 'LangSmith is a platform for LLM application development, monitoring, and testing. In this guide, we’ll highlight the breadth of workflows LangSmith supports and how they fit into each stage of the application development lifecycle. We hope this will inform users how to best utilize this powerful platform or give them something to consider if they’re just starting their journey.',
'language': 'en'
})],
'answer': 'LangSmith can help test your LLM applications by providing features such as creating datasets for running tests, allowing for custom evaluations, offering a comparison view to track performance across different configurations, providing a playground environment for rapid iteration and experimentation, supporting beta testing with feedback collection and run annotation, enabling feedback scores on logged traces, allowing annotation of traces by annotators, and facilitating the addition of runs to datasets for refining and improving performance. Additionally, LangSmith offers production monitoring, online evaluations, automations for real-time processing and scoring, threads view for tracking multi-turn interactions, and monitoring and A/B testing capabilities to track key metrics and test changes in prompt, model, or retrieval strategy.'
}위 결과의 소스
from langchain_core.messages import HumanMessage, AIMessage
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
# loader
loader = WebBaseLoader("https://docs.smith.langchain.com/user_guide")
docs = loader.load()
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)
#retriever
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
("user", "Given the above conversation, generate a search query to look up to get information relevant to the conversation")
# 위의 대화를 바탕으로 대화와 관련된 정보를 얻기 위해 조회할 검색어를 생성합니다.
])
retriever_chain = create_history_aware_retriever(llm, retriever, prompt)
prompt = ChatPromptTemplate.from_messages([
("system", "Answer the user's questions based on the below context:\n\n{context}"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
])
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever_chain, document_chain)
chat_history = [HumanMessage(content="Can LangSmith help test my LLM applications?"), AIMessage(content="Yes!")]
print(retrieval_chain.invoke({
"chat_history": chat_history,
"input": "Tell me how"
}))
4. Agent
: LLM을 활용하여 질문에 답변하기 위해 데이터를 가져와야 하는지 여부를 결정하는 에이전트를 구축합니다.
우리는 지금까지 각 단계가 미리 알려진 체인의 예를 만들었습니다.
우리가 만들 마지막 것은 LLM이 수행할 단계를 결정하는 에이전트입니다.
참고: OpenAI 모델을 사용하여 에이전트를 생성하는 방법만 보여줍니다.
에이전트를 구축할 때 가장 먼저 해야 할 일 중 하나는 에이전트가 액세스할 수 있는 도구를 결정하는 것입니다.
이 예시에서는 에이전트에게 두 가지 도구에 대한 액세스 권한을 부여합니다.
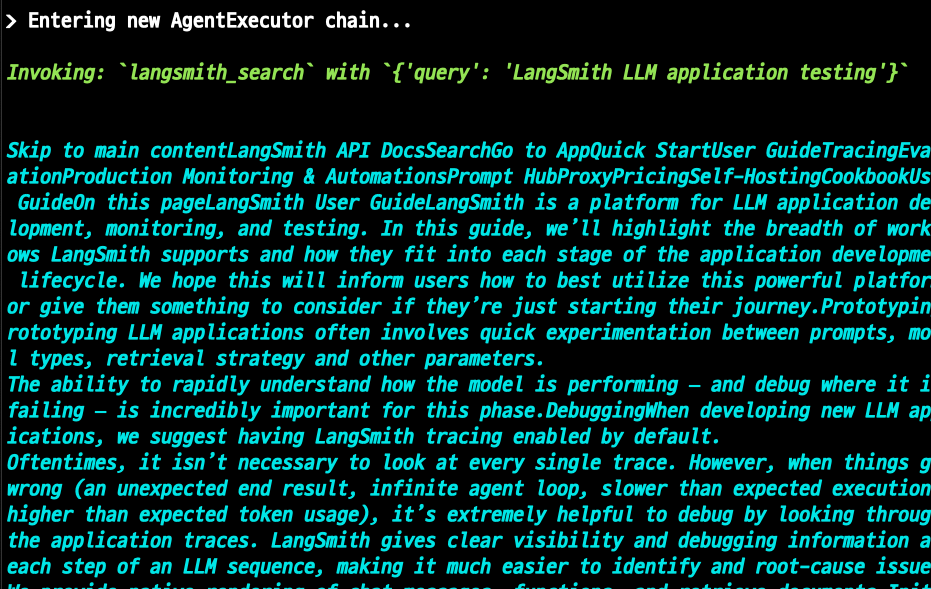
1. 방금 만든 Retriever입니다. 이를 통해 LangSmith에 관한 질문에 쉽게 답할 수 있습니다.
2. 검색 도구. 이를 통해 최신 정보가 필요한 질문에 쉽게 답할 수 있습니다.
먼저 방금 만든 Retriever에 대한 도구를 설정해 보겠습니다.
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"langsmith_search",
"Search for information about LangSmith. For any questions about LangSmith, you must use this tool!",
)우리가 사용할 검색 도구는 Tavily 입니다.
이를 위해서는 API 키가 필요합니다(무료!).
해당 플랫폼에서 생성한 후 환경 변수로 설정해야 합니다.
우선 api키를 얻기 위해 https://tavily.com/에 접속하여 Free의 Get started 를 합니다.
로그인을 하면 바로 Api Key를 알려줍니다

key 복사 후에 TAVILY_API_KEY라는 이름으로 export 해줍니다.
이제 도구가 있으므로 이를 사용할 에이전트를 만들 수 있습니다
우선 langchain hub를 인스톨 해줍니다.
pip3 install langchainhub기존 위에서 작성했던 소스와 tool&agent executor를 작성해줍니다.
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain.tools.retriever import create_retriever_tool
from langchain_core.messages import HumanMessage, AIMessage
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
from langchain import hub
from langchain.agents import create_openai_functions_agent
from langchain.agents import AgentExecutor
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
# loader
loader = WebBaseLoader("https://docs.smith.langchain.com/user_guide")
docs = loader.load()
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)
#retriever
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# retriever tool
retriever_tool = create_retriever_tool(
retriever,
"langsmith_search",
"Search for information about LangSmith. For any questions about LangSmith, you must use this tool!",
)
search = TavilySearchResults()
tools = [retriever_tool, search]
# Get the prompt to use - you can modify this!
prompt = hub.pull("hwchase17/openai-functions-agent")
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input": "how can langsmith help with testing?"})result:

input:
agent_executor.invoke({"input": "what is the weather in SF?"})result:

input:
chat_history = [HumanMessage(content="Can LangSmith help test my LLM applications?"), AIMessage(content="Yes!")]
agent_executor.invoke({
"chat_history": chat_history,
"input": "Tell me how"
})result:
여기까지가 기본적인 agent셋팅까지 입니다.
이제 애플리케이션을 구축했으므로 이를 제공해야 합니다.
이것이 바로 LangServe가 등장하는 이유입니다.
LangServe는 개발자가 LangChain 체인을 REST API로 배포하는 데 도움을 줍니다.
LangChain을 사용하기 위해 LangServe를 사용할 필요는 없지만
이 가이드에서는 LangServe를 사용하여 앱을 배포하는 방법을 알아보겠습니다.
python은 어떻게 서버를 띄워야하는지 고민했었는데 지원을 해주고 있었습니다. good~
pip3 install "langserve[all]"
serve.py를 하나 만들어서 app를 serving해보겠습니다.
#!/usr/bin/env python
from typing import List
from fastapi import FastAPI
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.tools.retriever import create_retriever_tool
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain import hub
from langchain.agents import create_openai_functions_agent
from langchain.agents import AgentExecutor
from langchain.pydantic_v1 import BaseModel, Field
from langchain_core.messages import BaseMessage
from langserve import add_routes
# 1. Load Retriever
loader = WebBaseLoader("https://docs.smith.langchain.com/user_guide")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings()
vector = FAISS.from_documents(documents, embeddings)
retriever = vector.as_retriever()
# 2. Create Tools
retriever_tool = create_retriever_tool(
retriever,
"langsmith_search",
"Search for information about LangSmith. For any questions about LangSmith, you must use this tool!",
)
search = TavilySearchResults()
tools = [retriever_tool, search]
# 3. Create Agent
prompt = hub.pull("hwchase17/openai-functions-agent")
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 4. App definition
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple API server using LangChain's Runnable interfaces",
)
# 5. Adding chain route
# We need to add these input/output schemas because the current AgentExecutor
# is lacking in schemas.
class Input(BaseModel):
input: str
chat_history: List[BaseMessage] = Field(
...,
extra={"widget": {"type": "chat", "input": "location"}},
)
class Output(BaseModel):
output: str
add_routes(
app,
agent_executor.with_types(input_type=Input, output_type=Output),
path="/agent",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)동작해보면 아래와 같이 서버가 띄워집니다.

8000포트에 붙어서 /agent/playground로 접속해보면 아래와 같이 웹사이트가 하나 나옵니다!
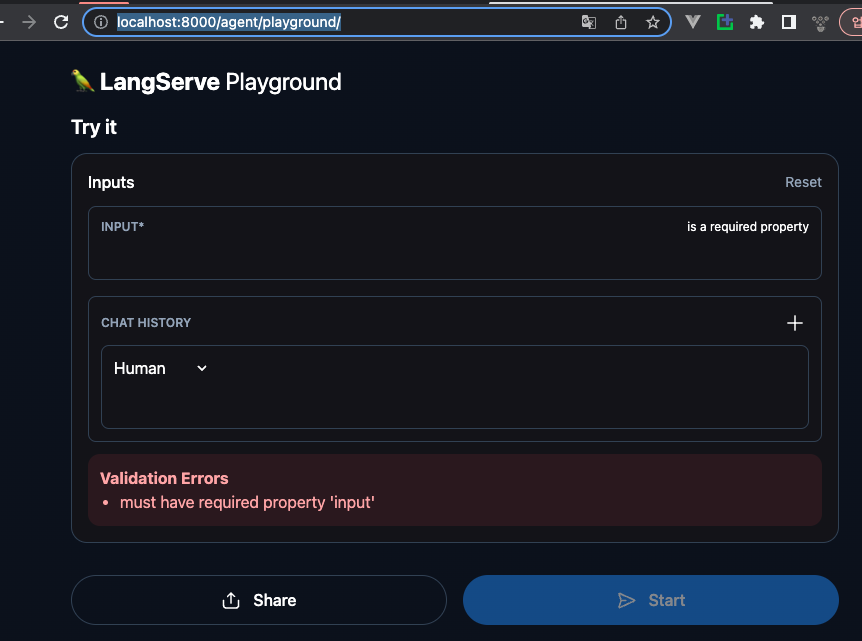
아래처럼 input등을 넣고 테스트 진행

error 발생!
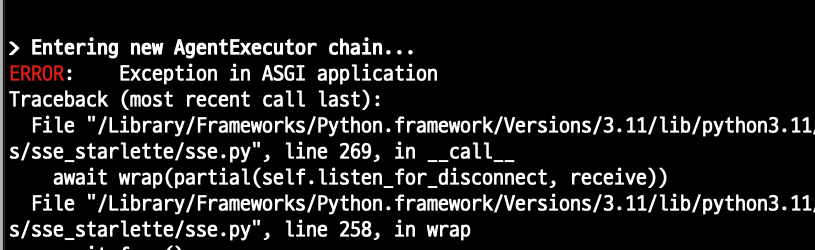
sse관련 최신 업데이트

기존 오류와 동일하게 발생 함.
input만 넣고 해보았는데 동작 잘함.

Chat History에서 오류가 발생!
소스를 살펴보니 Chat History를 처리 해주는 부분이 없어서 나는것 같습니다.
클라이언트 소스는 아래와 같습니다.
client.py
from langserve import RemoteRunnable
remote_chain = RemoteRunnable("http://localhost:8000/agent/")
remote_chain.invoke({
"input": "how can langsmith help with testing?",
"chat_history": []
})
참고문서 : https://python.langchain.com/docs/get_started/quickstart/
'A.I > RAG' 카테고리의 다른 글
| ai? 맨땅에 헤딩 -4(langChain): vector DB 간단 사용! (0) | 2024.04.29 |
|---|---|
| ai? 맨땅에 헤딩 -3(langChain) : 주요 컴포넌트 체크! (0) | 2024.04.26 |
| ai? 맨땅에 헤딩 -1(langChain) : ai와 공생하기! (0) | 2024.04.19 |
| PlaybackController Interface (0) | 2017.05.26 |
| Understanding Alerts (0) | 2017.05.26 |



