Data Platform/Spark
[Spark-Study] Day-5 인텔리제이에서 실습
태하팍
2021. 8. 12. 13:36
반응형
2021.06.14 - [Study/Study group] - [Spark-Study] Day-1
2021.06.24 - [Study/Study group] - [Spark-Study] Day-2
2021.07.01 - [BigDATA/spark] - [Spark-Study] Day-3
2021.08.05 - [BigDATA/spark] - [Spark-Study] Day-4
관련 github : https://github.com/databricks/LearningSparkV2
챕터3의 소스를 동작하기 위해 다시 프로젝트를 생성해보았다.
git clone https://github.com/databricks/LearningSparkV2.git
소스를 클론해 오고 IDE에서 오픈하였다.

main소스에서는 package를 chapter3으로 수정.
실행을 하기위해 설정은 아래와 같이 하였다.

물론 i-trem에서도 sbt를 통해 바로 실행이 가능하다.
/usr/local/Cellar/apache-spark/3.1.2/bin/spark-submit --master local --deploy-mode client --class chapter3.Example3_7 --name spark-submit --driver-memory 1024M --driver-cores 1 --executor-memory 1G /Users/terrypark/Joy/LearningSparkV2/chapter3/scala/target/scala-2.12/main-scala-chapter3_2.12-1.0.jar /Users/terrypark/Joy/LearningSparkV2/chapter3/scala/data/blogs.json
아래와 같은 결과가 도출!
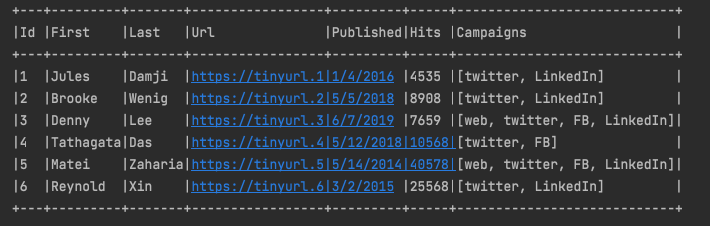

다음 시간에는 spark-shell을 통해 여러가지 실습을 해보자!
반응형